Data Loading
The pysat.Instrument.load() method takes care of a lot of the
processing details needed to produce a scientifically useful data set. The
image below provides an overview of this process.
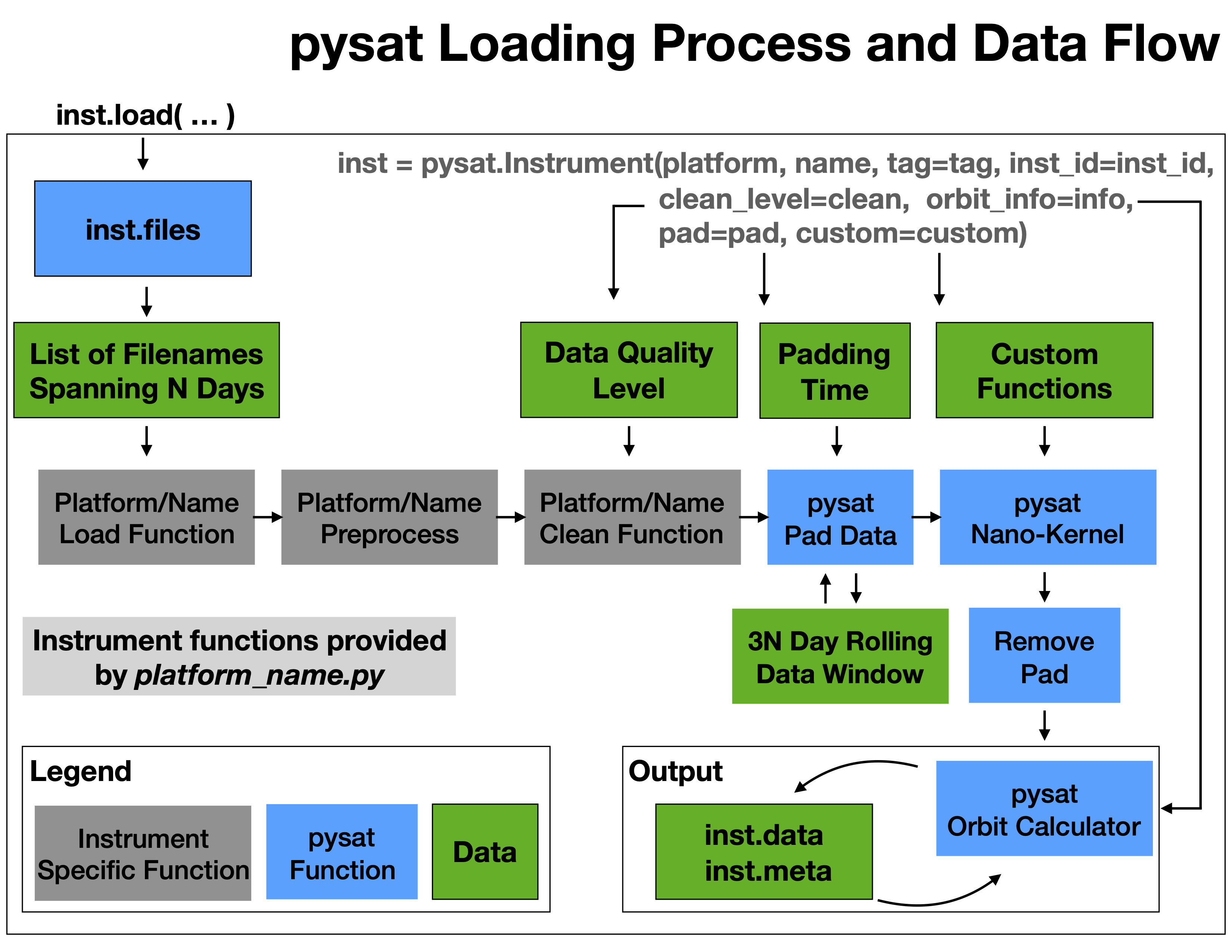
Load Data
A single day (or file) may be loaded by the user into a pysat.Instrument object
using the Instrument.load() method by specifying a year and day of
year, date, or filename.
import pysat
import datetime as dt
# Set user and password for Madrigal
username = 'Firstname+Lastname'
password = 'email@address.com'
# Initialize the instrument, passing the username and password to the
# standard routines that need it
import pysatMadrigal as pysatMad
dmsp = pysat.Instrument(inst_module=pysatMad.instruments.dmsp_ivm, tag='utd',
inst_id='f12', user=username, password=password)
# Define date range to download data
start = dt.datetime(2001, 1, 1)
stop = dt.datetime(2001, 1, 2)
# Download data
dmsp.download(start, stop)
# Load by year, day of year
dmsp.load(2001, 1)
# Load by date
dmsp.load(date=start)
# Load by filename from string
dmsp.load(fname='dms_ut_20010101_12.002.hdf5')
# Load by filename in tag
dmsp.load(fname=dmsp.files[0])
# Load by filename in tag and specify date
dmsp.load(fname=dmsp.files[start])
When the pysat.Instrument.load() method runs, it stores the intrument
data in the pysat.Instrument.data attribute,
# Display all data
dmsp.data
which maintains full access to the underlying data library functionality.
pysat supports the use of two different data structures. You can either use a
pandas
DataFrame,
a highly capable class with labeled rows and columns, or an xarray
DataSet
for data sets with more dimensions. The type of data class is flagged using
the attribute pysat.Instrument.pandas_format. This is set to
True if a pandas.DataFrame is returned by the corresponding
Instrument.load() method and False if a xarray.Dataset
is returned.
Load Data Range
pysat also supports loading data from a range of files or file dates. Given the
potential change in user expectation when supplying a list of filenames to load
instead of loading using a range of dates, pysat has adopted a nomenclature to
consistently distinguish between inclusive and exclusive bounds. Keywords in
pysat with end_* are an exclusive bound, similar to slicing
numpy.ndarray objects, while those with stop_* are an
inclusive bound. The starting index is always inclusive.
Note
Keywords for date or filename ranges that begin with end
are used as an exclusive terminating bound, while keywords that begin
with stop are used as an inclusive bound.
Loading a range of data by year and day of year. Termination bounds are exclusive.
# Load by year, day of year from 2001, 1 up to but not including 2001, 3
dmsp.load(2001, 1, end_yr=2001, end_doy=3)
# The following two load commands are equivalent
dmsp.load(2001, 1, end_yr=2001, end_doy2=2)
dmsp.load(2001, 1)
Loading a range of data using datetime.datetime limits. Termination
bounds are exclusive.
# Load by datetimes
dmsp.load(date=dt.datetime(2001, 1, 1),
end_date=dt.datetime(2001, 1, 3))
# The following two load commands are equivalent
dmsp.load(date=dt.datetime(2001, 1, 1),
end_date=dt.datetime(2001, 1, 2))
dmsp.load(date=dt.datetime(2001, 1, 1))
Loading a range of data using filenames. Termination bounds are inclusive.
# Load a single file
dmsp.load(fname='dms_ut_20010101_12.002.hdf5')
# Load by filename, from fname up to and including stop_fname
dmsp.load(fname='dms_ut_20010101_12.002.hdf5',
stop_fname='dms_ut_20010102_12.002.hdf5')
# Load by filenames using the DMSP object to get valid filenames
dmsp.load(fname=dmsp.files[0], stop_fname=dmsp.files[1])
# Load by filenames. Includes data from 2001, 1 up to but not
# including 2001, 3
dmsp.load(fname=dmsp.files[dt.datetime(2001, 1, 1)],
stop_fname=dmsp.files[dt.datetime(2001, 1, 2)])
For small size data sets, such as space weather indices, pysat also supports loading all data at once.
# F10.7 data
import pysatSpaceWeather
f107 = pysat.Instrument(inst_module=pysatSpaceWeather.instruments.sw_f107)
# Load all F10.7 solar flux data, from beginning to end.
f107.load()
Clean Data
Before data is available in pysat.Instrument.data it passes through
an instrument specific cleaning routine. The amount of cleaning is set by the
clean_level attribute, which may be specified at instantiation. The
level defaults to 'clean'.
dmsp = pysat.Instrument(platform='dmsp', name='ivm', tag='utd',
inst_id='f12', clean_level=None)
dmsp = pysat.Instrument(platform='dmsp', name='ivm', tag='utd',
inst_id='f12', clean_level='clean')
Four levels of cleaning may be specified,
clean_level |
Result |
clean |
Generally good data |
dusty |
Light cleaning, use with care |
dirty |
Minimal cleaning, use with caution |
none |
No cleaning, use at your own risk |
The user provided cleaning level is can be retrieved or reset from the attribute
Instrument.clean_level. The details of the cleaning will
generally vary greatly between instruments. Many instruments provide only two
levels of data: clean or none.
By default, pysat is configured to use 'clean' as the default value
for clean_level. This setting may be updated using
Parameters.